Web Audit: Tag Presence Scanner Automated Python Utility
Introduction#
The primary goal of any web analytics program is to enable stakeholders with data-driven decision making. There are multiple stakeholders in an organization that rely heavily on these metrics for key decisions be it optimization related, campaign performance related or content performance related. This leads to our topic for the day which is accuracy of data. How much can we trust our data for decisions?
The reporting analysts are often asked about reliability of data and the accuracy of the metrics by stakeholder but we tend to rely on analytics tools to a great degree for accuracy, however the data accuracy by a tool is as good as our data quality process.
Web Audits#
The idea of Web Audits (or Site Audit) is basically QAing our web site tags in order to ensure our data collection strategy and reporting are aligned to highest level of accuracy. The defects noted/found by web audits can be used to raise an alarm or annotate the rise or fall in a metric, this enables stakeholder to understand the metric discrepancy and take action accordingly.
One of such common defects is pages missing TMS embeds, this could be GTM container snippet on page or Adobe DTM/Launch header tags. Missing these tags on pages disables analytics tracking and we loose on analytics data. Having an audit process in place ensures that our pages have correct embeds present on them and new pages/sections added have embeds scripts available in order for analytics tracking.
Automate Web Audit Using Python#
In order to automate the process of web audits and review GTM container/Adobe Launch embeds on page, I have created a basic crawler script that can crawl all pages on a site and check for tag manager embeds. The outputs are written into a CSV file for review.
This is a basic crawler built in python, it can be used to crawl a site using start page/homepage. The crawler will automatically pull anchor hrefs from html anchor tags and navigate to them. It is setup using BeautifulSoup and requests module in python and checks page for DTM/Launch embeds and Google Tag Manager (GTM) container scripts on page. It can be useful to find pages missing tags/embeds on site.
Please feel free to fork source code here: https://github.com/appuriabhi/tms_scanner
Installation and Dependencies#
The below step by step process will guide you to install dependencies:
Since this script is built in python, we need to have python >= 3.6 installed in system. If you don’t have python already installed you can download and install from here: https://www.python.org/downloads/. Make sure to add Python to PATH or you will have to do it manually later. More information can be found here: https://www.geeksforgeeks.org/download-and-install-python-3-latest-version
The script relies on following python packages: requests, BeautifulSoup, pandas, time (built-in), tqdm, csv (built-in),pyfiglet. In order to install these packages simply open windows powershell / command prompt and type for each package:
pip3 install pandas
- Once we have dependencies resolved - we can fork git repository (https://github.com/appuriabhi/tms_scanner) or zip download source code files.
Setup First Audit#
The process of setting up an audit is straight forward. Please refer below for step by step instructions:
- The utility can be rendered using command:
python tms-checker.py
- Once the utility program is started, we can see the below screen:
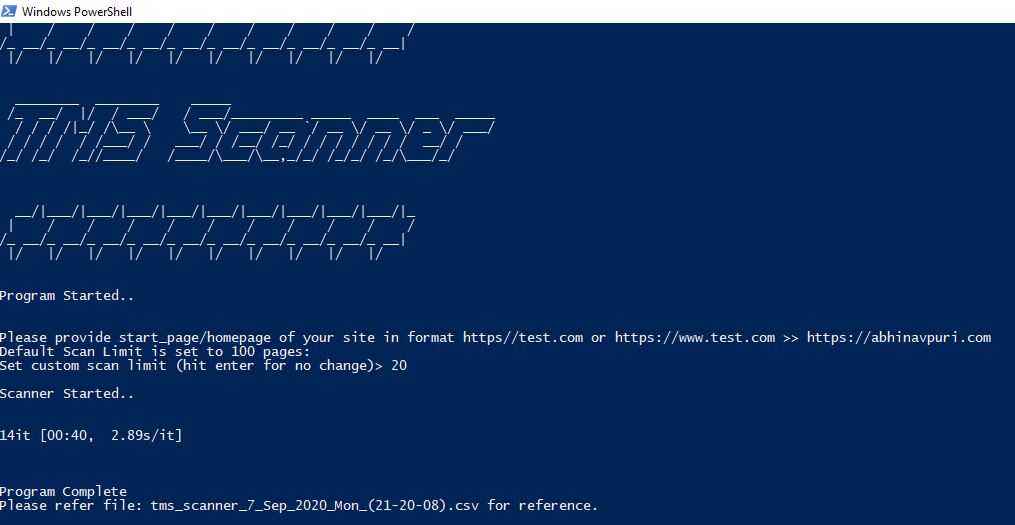
- The script asks for basic details like homepage/or starting url, the format needs to be consistent in order for utility to work:
https://abhinavpuri.com
The script scans 100 pages by default until specified using second input asking custom scan limit.
Once scan is completed, the crawler generates a CSV file with page url, status code, page title, gtm container embed and launch/dtm embeds. Sample Filename: tms_scanner_7_Sep_2020_Mon_(21-20-08)

Closing Notes#
This utility can be a starting point for automated web audits that can scan our site pages and provide us with tag management embeds information. We can also build a metric validation utility that can track basic pageview tracking calls form leading analytics tools in order to verify tracking and ensure data collection is smooth for our analysis.
Next up we can deploy our script on cloud platform and let it run via cron job with automated email notifications on desired frequency (weekly/monthly) and attached CSV with scan results. Stay tuned for next blog post with steps to deploy our script to cloud.
If you enjoyed this post, I’d be very grateful if you’d help it spread by sharing it on Twitter/LinkedIn. Thank you!