ATLAS: Automated Web Debugger
Introduction#
Data Validation is an essential step so we can make better decisions based upon the data collected. We have various data collection tags implemented on our web properties and auditing them for data quality is a tedious task.
There are multiple automated web audit/testing tools that can perform this job in an effective manner also make clients confident about the data collected but these come with a subscription cost.
Manual testing of marketing tags on the website is a tiresome job since there can be hundreds of pages and often require additional resources to keep track of implementation on an ongoing basis.
Web Audits / Tag Validation#
The process of Web Auditing (or Site Auditing) is the process of testing website tags for potential errors in data collection. There can be plenty of tag implementation issues like duplicate tags, missing tags on the website that can affect the data collection strategy and result in incomplete data for analysis.
Setting up a regular website tag validation process helps ensure the issues/defects can be found proactively and fixed, which will make sure the data collected can be trusted with confidence for better decision making.
ATLAS: Automated Web Debugger#
I have built an automated python utility that can help us reduce manual testing efforts and get the marketing tags audit results for pages on the website. This utility is built upon my previous tms_crawler utility and extends its features as well.(Previous Post - https://www.abhinavpuri.com/blog/tag-scanner/)
This automated web crawler script is built in python. It will crawl the website using the start page/base domain provided and automatically check for the supported list of tags (below) rendering them in chromium (headless browser). The marketing tags network requests are intercepted and extracted to be written in separate CSV files for each vendor as the output file format.
Supported List Of Tags#
Adobe Analytics > Both ‘GET’ and ‘POST’ request for Adobe Analytics tracking calls are supported. Currently, we’re supporting pageviews [s.t()] tracking calls only. Suppot for custom link tracking calls [s.tl()] is planned for future release.
Adobe Launch/DTM Embeds > The script will extract adobe launch embeds/adobe dtm embeds present in page source code.
Google Analytics > The script supports both ‘GET’ and ‘POST’ requests for google analytics tracking call. The custom interaction calls are not fully supported. If you have implemented scrollDepth tracking on your website you might see custom interaction calls with ‘event’:‘Not Found’ in CSV export.
Google Tag Manager (GTM) Embeds > The script will extract google tag manager container embeds present in page source code.
Adobe Target > Tracking calls to adobe target are also supported. The script will intercept both ‘GET’ and ‘POST’ requests to adobe target this should cover both mbox.js and at.js libraries.
Facebook Pixels > The facebook event pixels are also tracked and supported. The CSV output file will contain all FB tags fired on the page.
Doubleclick Floodlight Tags >The script also supports floodlight tags implemented on the webpage. The CSV output file will report on all floodlight tags fired along with attributes: ‘src’, ‘type’, and ‘cat’ in the network calls.
Decibel Insight >The decibel insights global page load requests are also supported. The output file will also report on ‘accountNumber’ and ‘da_websiteId’ as well.
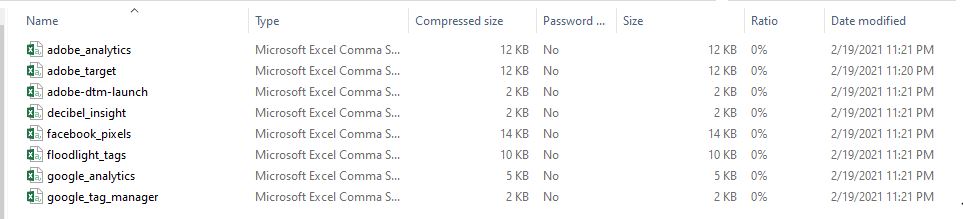
Cookies > The utility also extracts first party cookies set on web page and write them to CSV file.
Installation and Dependencies#
The below step by step process will guide you to install dependencies:
Since this script is built in python, we need to have python >= 3.6 installed on the system. If you don’t have python already installed you can download and install it from here: https://www.python.org/downloads/. Make sure to add Python to PATH or you will have to do it manually later. More information can be found here: https://www.geeksforgeeks.org/download-and-install-python-3-latest-version
The utility source code files on git repository: (https://github.com/appuriabhi/ATLAS-Automated-Web-Debugger.git). Please feel free to fork or zip download source code files.
The script relies on the below packages for rendering -
- requests==2.25.1
- pyppdf==0.0.12
- beautifulsoup4==4.6.0
- pyppeteer==0.2.5
- websockets==8.1
- pyee==6.0.0
- zipp==3.4.0
- urllib3==1.26.3
- lxml==4.6.2I have included the requirement.txt file to install package dependencies easily using the command:
pip install -r requirements.txt
// use command in script directory
Pyppeteer Package > The script uses pyppeteer python module which is unofficial python port of puppeteer JavaScript (headless) chrome/chromium browser automation library. The package will require a chromium webdriver for execution and will install automatically on the first run (size~100mb).
Running First Web Audit#
The process of execting audit is very simple. Please refer below for step by step instructions:
Step 1> Update the below variables to provide audit details in 'main.py' file and save.
# Initial Setup
start_page = 'https://abhinavpuri.com/'
# not setting page scan limit will throw error
limit = 5
# use below list to exclude specific diretory/pages
exclude_list = ['mailto:','javascript:','#','account','result']
# Setup complete
Step 2> Render utility in Poweshell/Command Prompt using the command below in utility directory -
python main.py
Step 3> Once the utility program is started, we can see the below screen: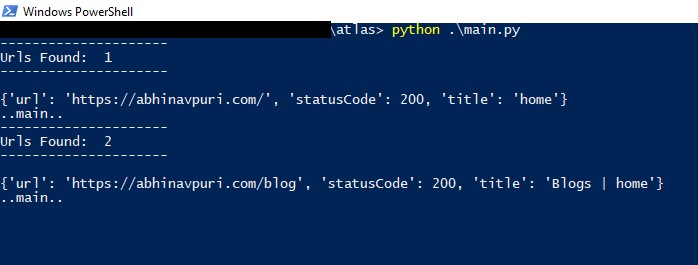
Step 4> Upon scan completion complete you will see similar screen below, the CSV files for each marketing tag vendor has been created and stored in zip file.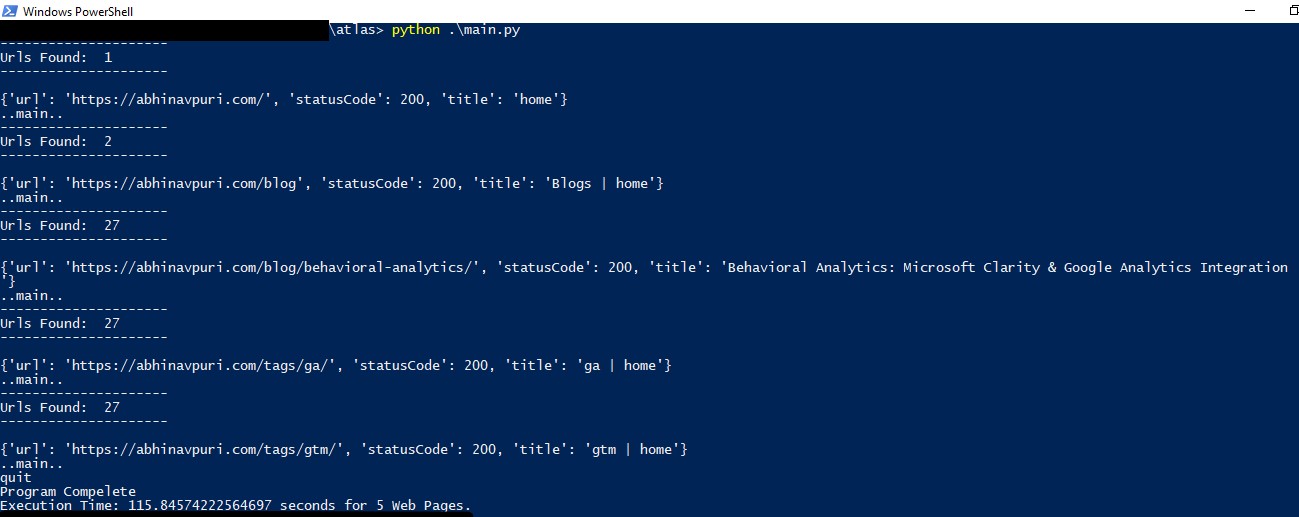
Step 5> You can extract ZIP file and access individual marketing vendor tag CSV file with export of all tags found on page for each vendor.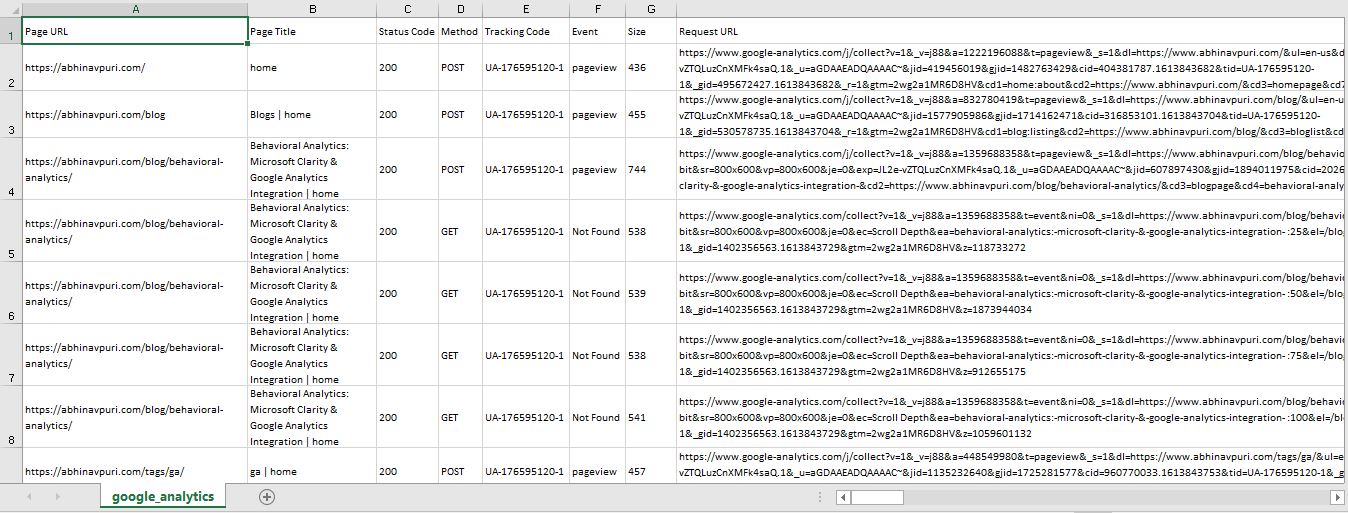
Closing Notes#
Automating the website tag auditing process by crawling and analyzing exports will ensure defects related to Mar-Tech tags implemented are discovered early and resolved. The confidence in data quality will help the clients building trust in reports generated.
The utility above has been tested on different websites, however, this is still the first version, and there is a lot of scope for improvement. I will work on adding more Mar-Tech solutions and features. If you find an issue with execution or installation. Please free to get in touch.
If you enjoyed this post, I’d be very grateful if you’d help it spread by sharing it on Twitter/LinkedIn. Thank you!